简介
Twist Bioscience 高通量抗体生产是一种从基因到蛋白质的工作流程,可生产数十种到数千种不同的抗体来筛选生物物理和药代动力学特性,从而打破这一瓶颈。Twist 的硅基 DNA 合成平台运行一次可精准写入数千个基因,从而能够快速、高通量生产用于研发和筛选的抗体。
奖励!我们为所有高通量抗体生产订单提供下游表征和筛选服务。此服务包括亲和力排序、表位分析等!
立即扩展抗体生产流程。您只需上传所需的抗体序列,剩下的交由 Twist 完成。了解更多关于如何从订购选项卡中订购抗体的信息!
工作原理
简言之,Twist 可将重、轻或单链可变序列合成并克隆到含有 Fc 的载体中。然后将成对的重链和轻链或单链基因转染到 HEK293 细胞中 4 天。收获含有分泌抗体的上清液,并使用蛋白质 A/G 进行纯化。分别使用 A280 和数字 CE-SDS 检查纯化抗体的浓度、大小和纯度信息。
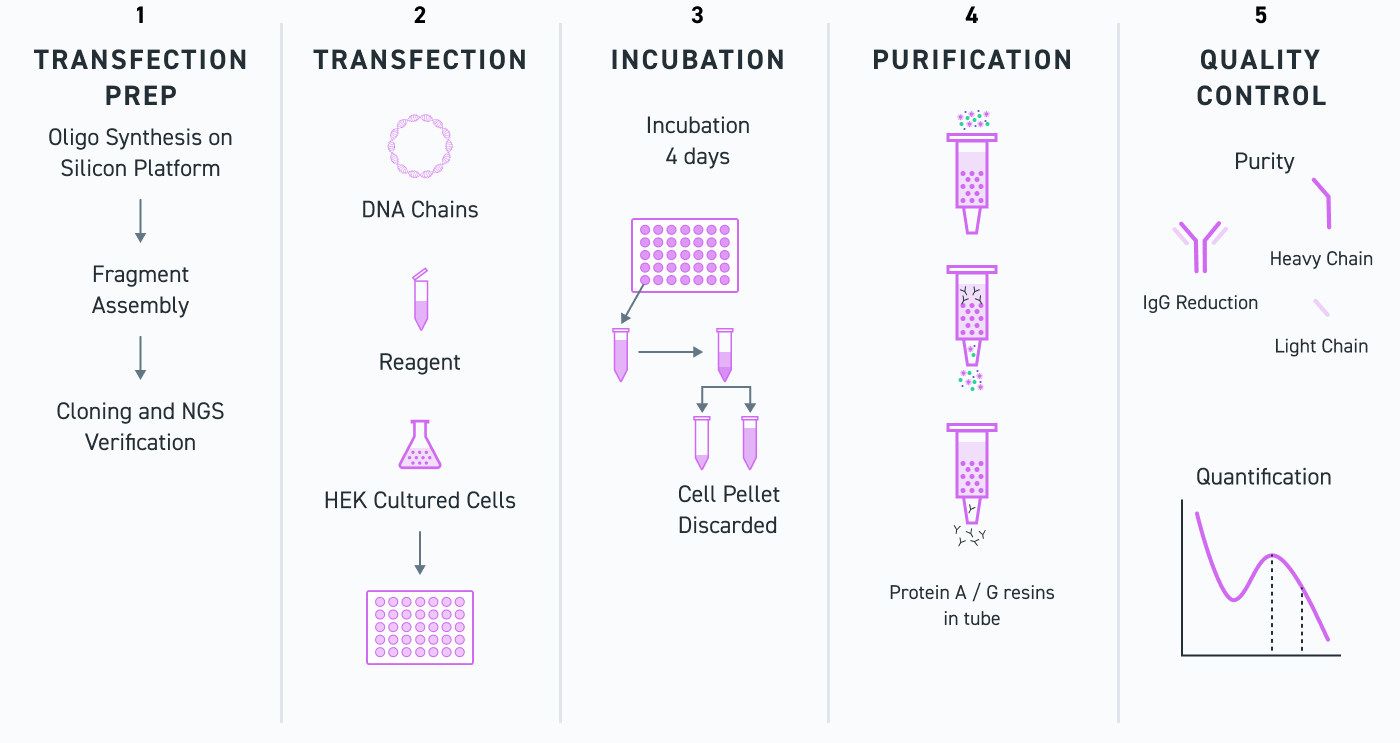
这个过程需要多长时间?
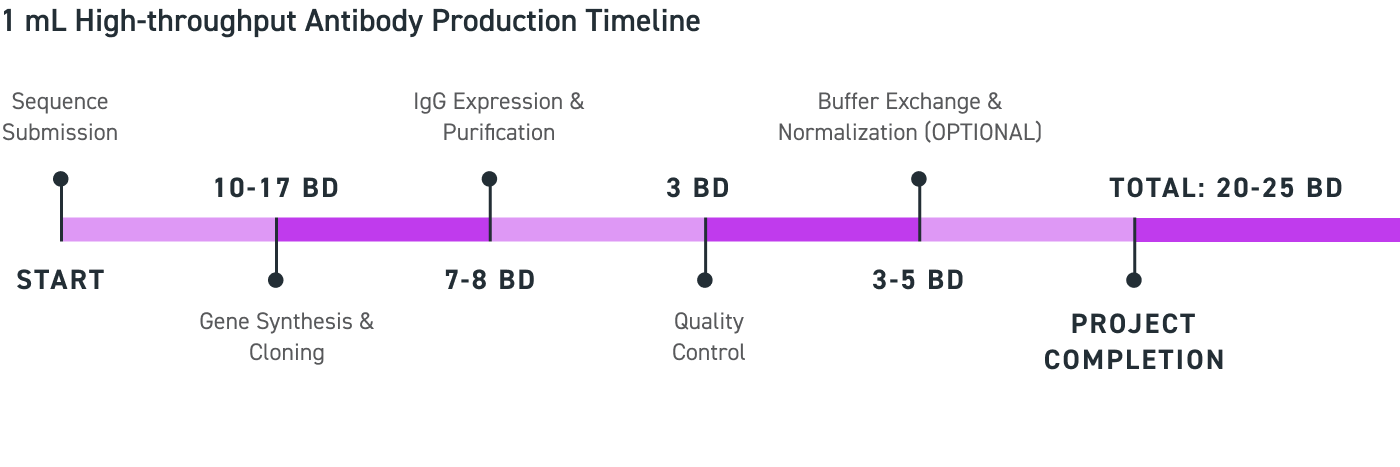
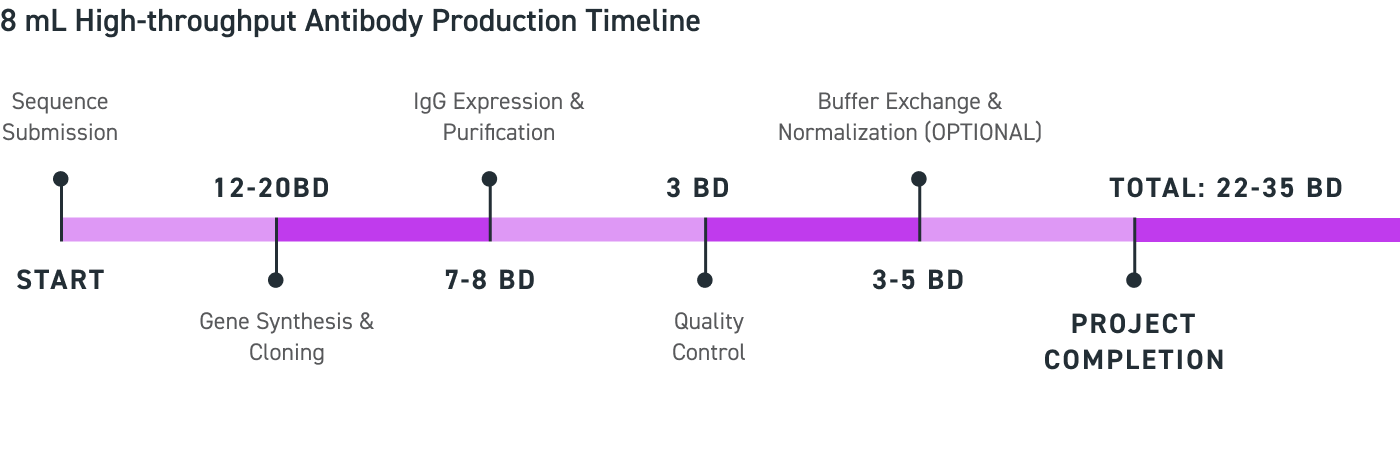
从序列提交到交付,对于 1mL 和 8mL 的订单,预计分别在 20-25 个工作日和 22-35 个工作日内交付抗体。


简介
Twist Bioscience 高通量抗体生产是一种从基因到蛋白质的工作流程,可生产数十种到数千种不同的抗体来筛选生物物理和药代动力学特性,从而打破这一瓶颈。Twist 的硅基 DNA 合成平台运行一次可精准写入数千个基因,从而能够快速、高通量生产用于研发和筛选的抗体。
奖励!我们为所有高通量抗体生产订单提供下游表征和筛选服务。此服务包括亲和力排序、表位分析等!
立即扩展抗体生产流程。您只需上传所需的抗体序列,剩下的交由 Twist 完成。了解更多关于如何从订购选项卡中订购抗体的信息!
工作原理
简言之,Twist 可将重、轻或单链可变序列合成并克隆到含有 Fc 的载体中。然后将成对的重链和轻链或单链基因转染到 HEK293 细胞中 4 天。收获含有分泌抗体的上清液,并使用蛋白质 A/G 进行纯化。分别使用 A280 和数字 CE-SDS 检查纯化抗体的浓度、大小和纯度信息。
需要扩大用于筛选的抗体的产能?
Twist 高通量抗体生产能够立即扩展您的抗体生产流程。您只需上传所需的抗体序列,剩下的交由 Twist 完成。
这个过程需要多长时间?
从序列提交到交付,对于 1mL 和 8mL 的订单,预计分别在 20-25 个工作日和 22-35 个工作日内交付抗体。
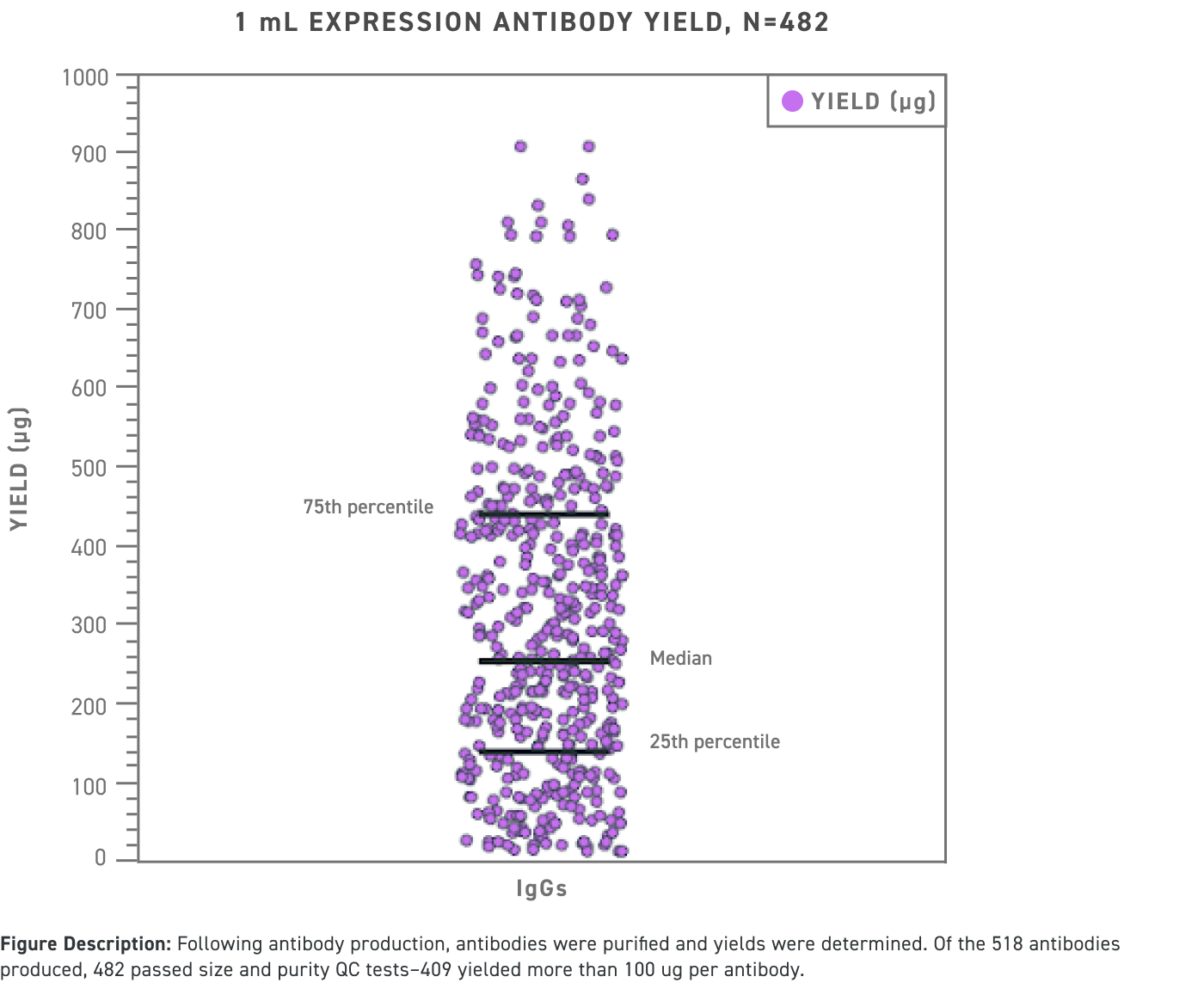
图像描述:在抗体产生之后,纯化抗体并测定产率。在产生的 518 个抗体中,有 482 种通过了大小和纯度质控测试——409 种抗体的产量超过 100 ug。
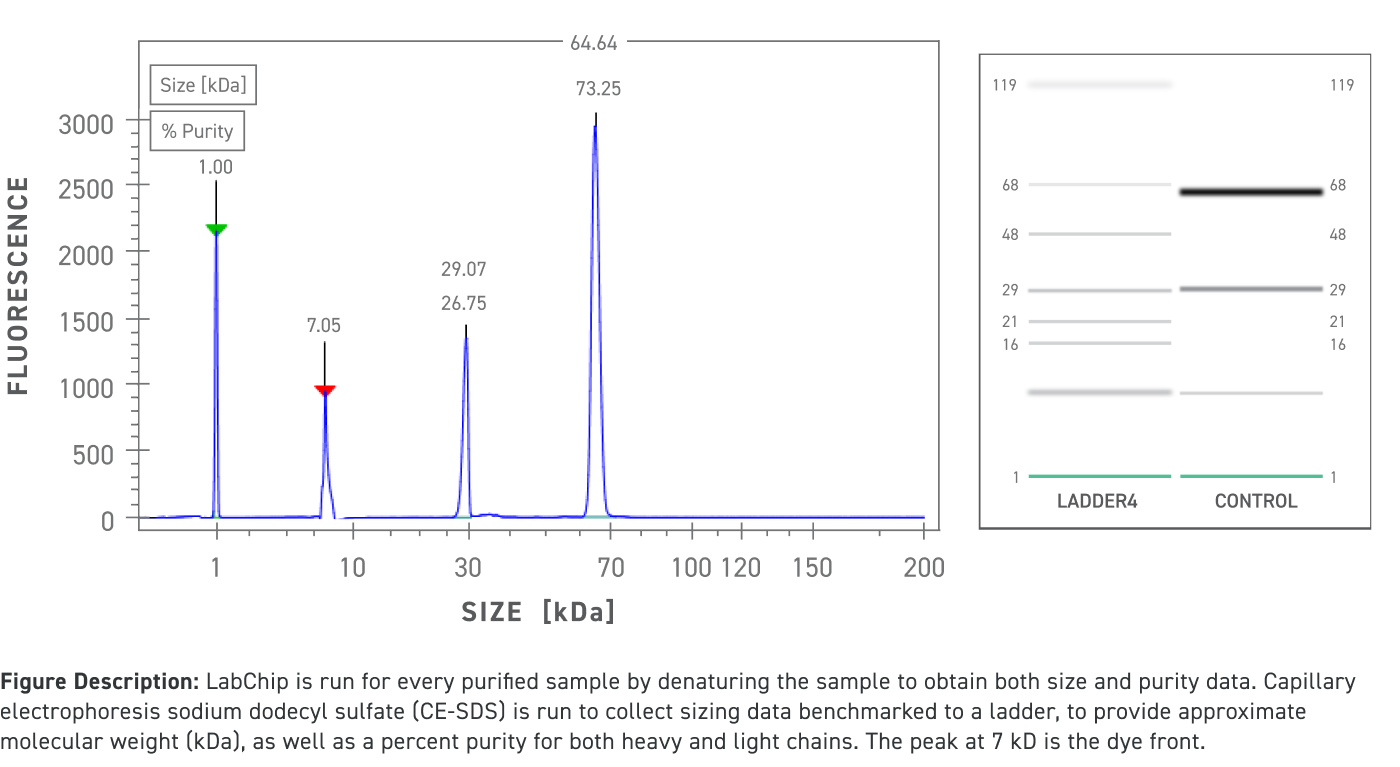
对每个纯化的样本运行 LabChip,通过对样本进行变性来获得大小和纯度数据。运行毛细管电泳十二烷基硫酸钠 (CE-SDS),根据梯度指标,获得大小数据,从而确定近似分子量 (kDa) 以及重链和轻链的纯度百分比。7 kD 处的峰是染料显色的起始位置。
想了解更多关于亲和力和滴度水平的数据吗?请下载我们的宣传单!
图像描述:在抗体产生之后,纯化抗体并测定产率。在产生的 518 个抗体中,有 482 种通过了大小和纯度质控测试——409 种抗体的产量超过 100 ug。
对每个纯化的样本运行 LabChip,通过对样本进行变性来获得大小和纯度数据。运行毛细管电泳十二烷基硫酸钠 (CE-SDS),根据梯度指标,获得大小数据,从而确定近似分子量 (kDa) 以及重链和轻链的纯度百分比。7 kD 处的峰是染料显色的起始位置。
想了解更多关于亲和力和滴度水平的数据吗?请下载我们的宣传单!


常规问题
交付形式
序列设计的资源和指导
-
AbYsis 为一种或多种抗体提供了综合、全面、带注释的序列评估。AbYsis 提供了抗体序列的全面区域划分,以快速确定可变区的起始和结束位点。并以列表的形式提供了对先导序列、FWK 序列和 CDR 序列以及柄端序列或恒定区序列的划分。
-
使用生物信息学程序将 abYsis 提供的注释应用于序列,有助于可视化和分离可变区。下面是导入 Geneious Prime 软件平台且应用了 abYsis 注释的序列示例。
-
另外一个可提供前导序列、可变区和恒定区全面划分的选项是 ANARCI。结果分析会以红色突出显示确切的可变区序列,接下来您可将此上传到我们电子商务网站上的抗体应用程序。ANARCI 还提供了有关轻链结构域类型和序列种属的详细信息。
-
请记住,可变区序列不能以甲硫氨酸 (M) 开头。如果您将上传以氨基酸 M 或核苷酸 ATG 开头的序列,并且计划使用 pTwist 载体,请联系我们的支持人员寻求帮助。
-
考虑到二硫键和其他特征之间的差异,将可变结构域从一个物种重组到另一个物种可能会比较复杂。默认情况下,Twist 电子商务平台不会更正任何这些问题。通常需要您自行说明和检查这些与重组相关的问题。如果您需要帮助,请联系我们的支持团队。
常规问题
交付形式
序列设计的资源和指导
-
AbYsis 为一种或多种抗体提供了综合、全面、带注释的序列评估。AbYsis 提供了抗体序列的全面区域划分,以快速确定可变区的起始和结束位点。并以列表的形式提供了对先导序列、FWK 序列和 CDR 序列以及柄端序列或恒定区序列的划分。
-
使用生物信息学程序将 abYsis 提供的注释应用于序列,有助于可视化和分离可变区。下面是导入 Geneious Prime 软件平台且应用了 abYsis 注释的序列示例。
-
另外一个可提供前导序列、可变区和恒定区全面划分的选项是 ANARCI。结果分析会以红色突出显示确切的可变区序列,接下来您可将此上传到我们电子商务网站上的抗体应用程序。ANARCI 还提供了有关轻链结构域类型和序列种属的详细信息。
-
请记住,可变区序列不能以甲硫氨酸 (M) 开头。如果您将上传以氨基酸 M 或核苷酸 ATG 开头的序列,并且计划使用 pTwist 载体,请联系我们的支持人员寻求帮助。
-
考虑到二硫键和其他特征之间的差异,将可变结构域从一个物种重组到另一个物种可能会比较复杂。默认情况下,Twist 电子商务平台不会更正任何这些问题。通常需要您自行说明和检查这些与重组相关的问题。如果您需要帮助,请联系我们的支持团队。

